Huffman Encoding
Low budget compressionHuffman encoding is a greedy algorithm that caters to the problem of assigning a unique code to a each character in a set of characters, given the frequency of occurrence of each character, such that there is no ambiguity in decoding the encoded string and the length of the encoded string is minimum. I’ll try to share my humble understandings of this wonderful algorithm in this post.
Some trivial approaches to the problem of encoding effectively#
Let us take a set of 4 characters and their corresponding frequencies as follows:
| Character | Frequency |
|---|---|
| a | 1 |
| b | 2 |
| c | 3 |
| d | 4 |
There are many ways to encode a string containing only these characters - using a binary number to represent a character is one of the most intuitive methods that comes to mind when we try to do so. There are 4 characters in total. To represent each of N (> 1) characters by a unique binary number, we need to have at least k digits in each binary number, related by the equation
$$k\ = \ \lceil log_2\ N\rceil$$
Here, $N$ is 4 and so, $k$ is 2. The possible binary codes that will be used are: 00, 01, 10, 11. These will be permuted with $a$, $b$, $c$, $d$. But, in each permutation, the total number of bits that will be present in the encoded string of a fixed string will be 2s, where s is the number of total number of characters present in the string, as each character in the string will be encoded by 2 digits, no matter what permutation we use. Take for example, we need to encode the string $abbcccdddd$ (easiest example I could think of). Suppose we take the permutation:
| Character | Code |
|---|---|
| a | 00 |
| b | 01 |
| c | 10 |
| d | 11 |
The encoded string will then be 00010110101011111111, a string of length 20. Even if we take any other permutation of codes, even then the length of the encoded string will remain same, but not the encoded string itself.
But, what if we can assign codes, not necessarily of a fixed length to each character, so that the length of the encoded string is lesser than what we have, and thus reduce the space occupied by the compressed string?
What we actually need to do can be expressed mathematically, as follows:
$${\text{minimize}}\ \sum_{i\ \in\ string}l_i\ f_i$$
where, $l_i$ represents the length of the code of character $i$ and $f_i$ represents the frequency of the character $i$.
We can easily see that assigning codes of same length to all characters is not going to be the solution to the above minimization problem in all cases.
One way to proceed is to start with the most frequently occuring character and assign it a code of minimum length, which will be 1. If there are many such characters, choose any one of them to have the minimum code length possible, starting from a length of 1. For eg., if the characters $x$, $y$, $z$, $w$ are the most frequently occuring characters in a string, and moreover, with the same frequency, we choose any one of them - say $w$ and assign it a code of length 1, then $z$ to have a code of length 2 and so on. Notice that I still haven’t told what the code is actually. I’ll come to that shortly.
You may ask, “Why not assign a code of length 1 to any 2 of $x$, $y$, $z$, $w$ and a code of length 2 to the other 2?” Though that will definitely minimize the length of the encoded string, we will face a slight problem there. When we do so, we might face ambiguity in decoding the encoded string, leaving the encoding useless. Let us see how.
Supposing I have the string $xyzwxxywzyzw$, which has to be encoded. All the four characters have same frequency 3. Let us assign the codes as follows.
| Character | Code |
|---|---|
| x | 0 |
| y | 1 |
| z | 10 |
| w | 01 |
Notice that the codes of length 2 are arbitrarily chosen from among 00, 01, 10, 11. We could have chosen any 2 of the 4.
Let us now encode the string according to this code: Substitute 0 in place of $x$, 1 in place of $y$ and so on, in the string $xyzwxxywzyzw$.
Thus, we get the encoded string to be: 011001001011011001. Let us try to decode this string. If you observe carefully, you can see that there are lot of ways in which the resultant string can be. 0 is $x$ and 1 is $y$. So, one possibility is $xyyxxyxxyxyyxyyxxy$. You can see that this is completely different from the string we had originally encoded. Why does this happen?
We observe that, in the code given to $z$ and $w$, the codes for $x$ and $y$ are embedded in them. If we encode $w$ or $z$, we get 01 or 10 respectively. But when we try to decode them, then the ambiguity arises - 01 can be both $w$ or $xy$. 10 can be both $z$ or $yx$.
Why does the ambiguity arise? Observe that the code for $x$ is a prefix of the code of $w$. So that means, whenever $w$ occurs, the encoded string can be decoded in two ways - $x$ (only after reading the first 1) or $w$, after reading the code 10. But how does one know when to choose which?
To overcome this ambiguity, we can use the help of a very useful data structure called tree, specifically binary tree.
A naive approach with trees#
To recall, our string was such that it had 4 characters - $a$, $b$, $c$ and $d$, appearing with frequencies 1, 2, 3 and 4 respectively. Our initial approach was to assign the more frequent characters with codes of lesser length. So, according to that logic, code length for different characters will be:
| Character | Code Length |
|---|---|
| d | 1 |
| c | 2 |
| b | 3 |
| a | 3 |
The 2 least frequent characters can have the same code length by having different Least Significant Bits (basically, the bit in the right-most place). So, $a$ and $b$ have the same code length.
Assigning codes to characters#
This is where trees come in. The procedure is to build a binary tree (a tree in which each node has at most 2 children) as follows:
Step - 1: Start with a root node.

Step - 2: Assign it’s left child to contain the character with highest frequency in the list of characters (if there are many such characters, assign any of them to this left child).
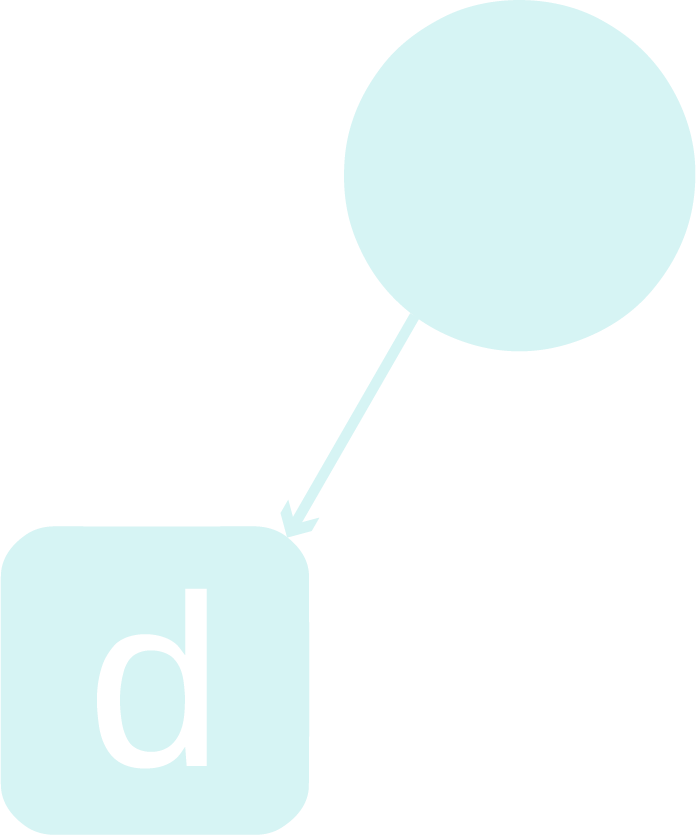
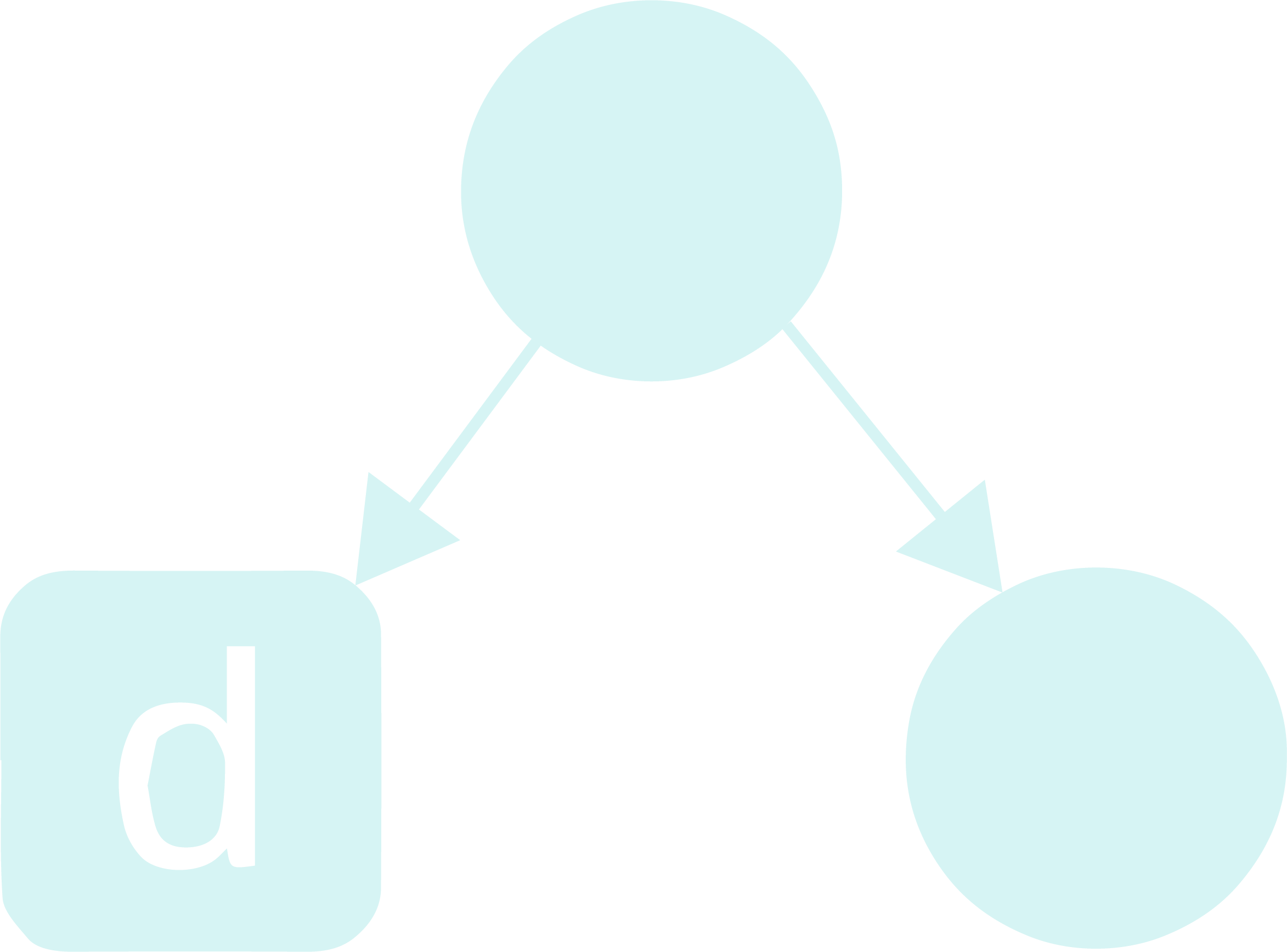
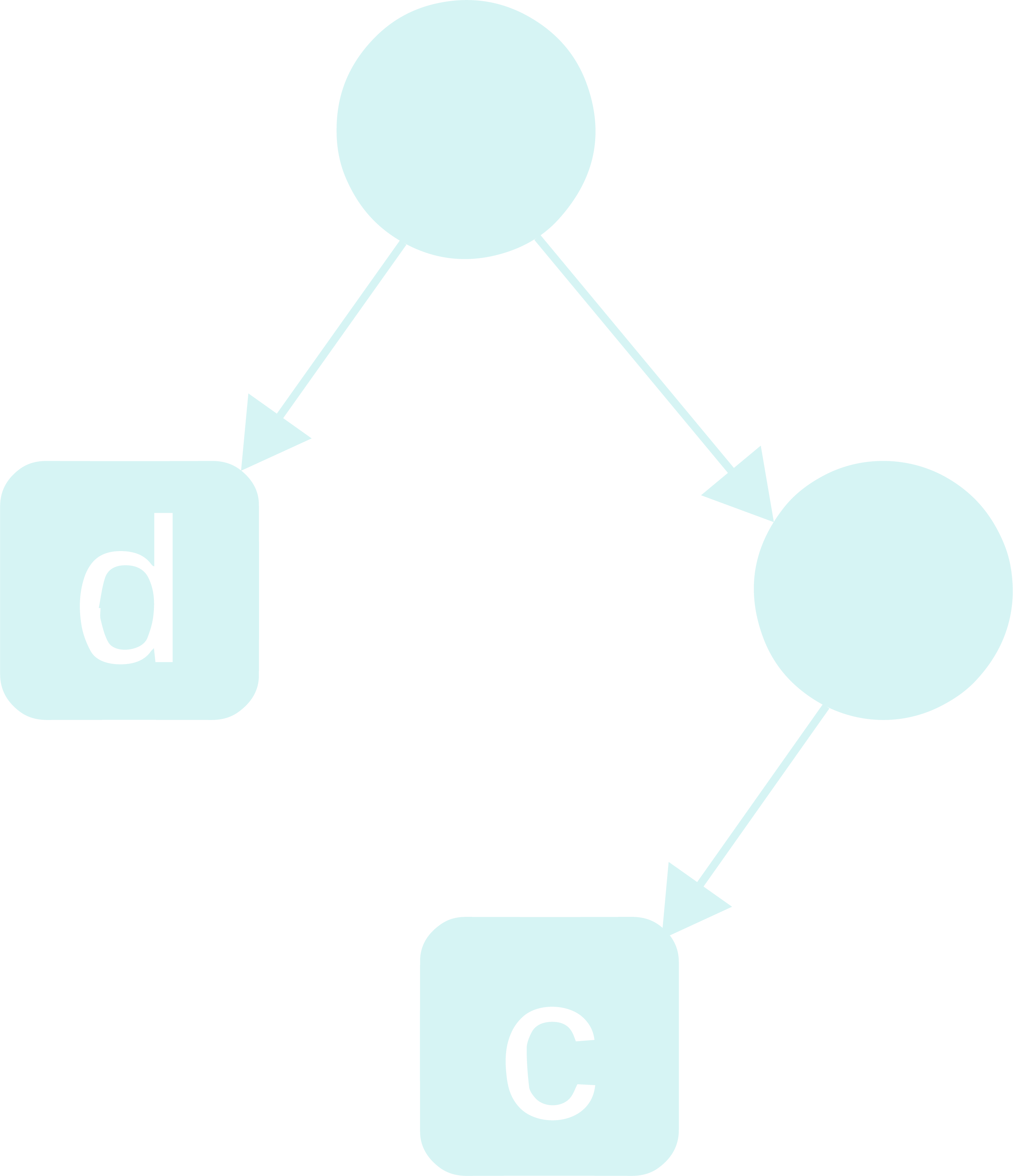
Step - 3: Repeat the steps 1-3 (not a typo. this is a recursive definition xD) with the right child of the current root as the new root and the list of characters as those characters that have not been assigned a place in the tree yet, till there is only 1 character left in the list, which will be the least frequent character.
 |
 |
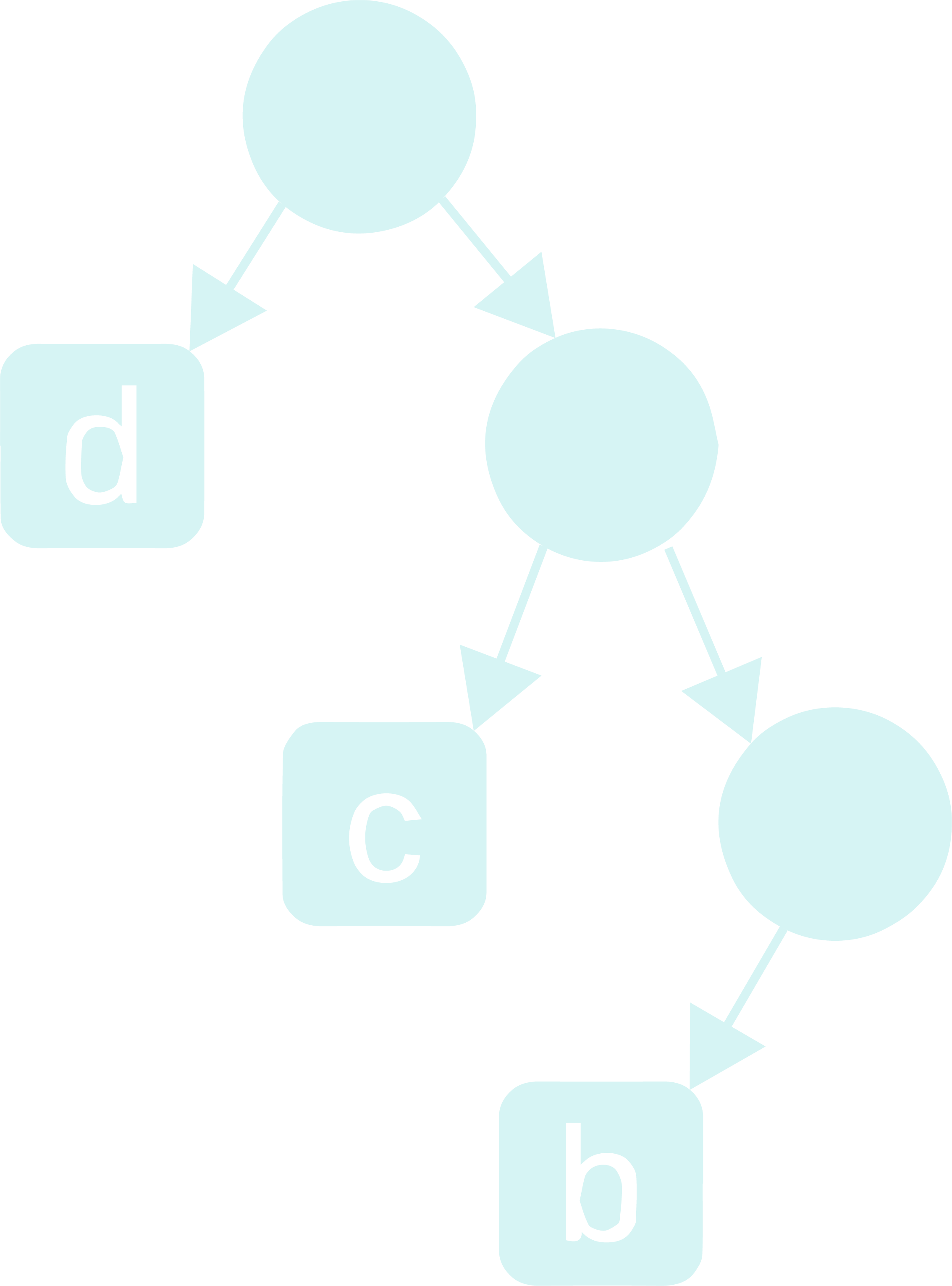 |
Step - 4: For the remaining character, assign it as the right child of the node that is most newly formed.
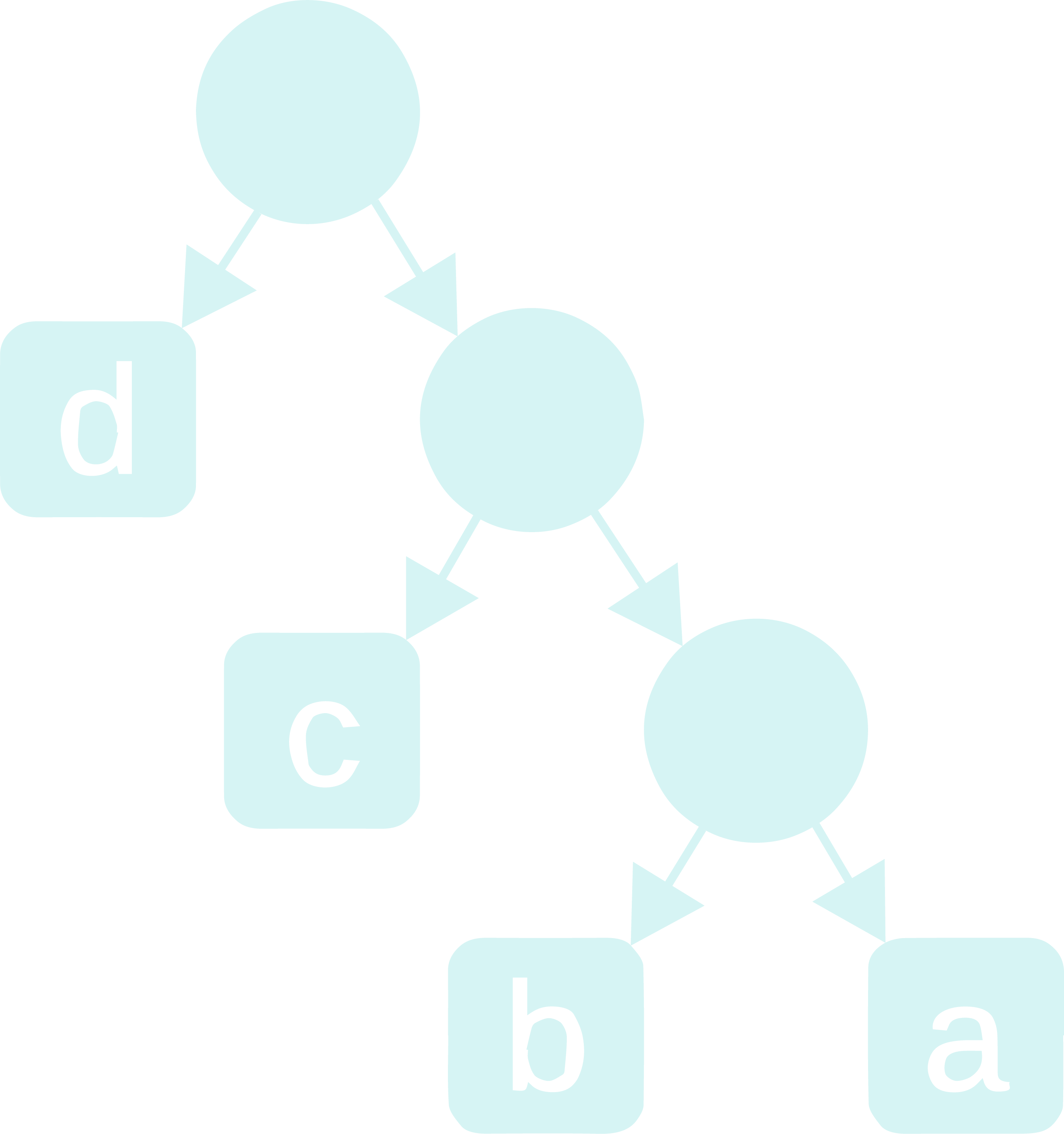
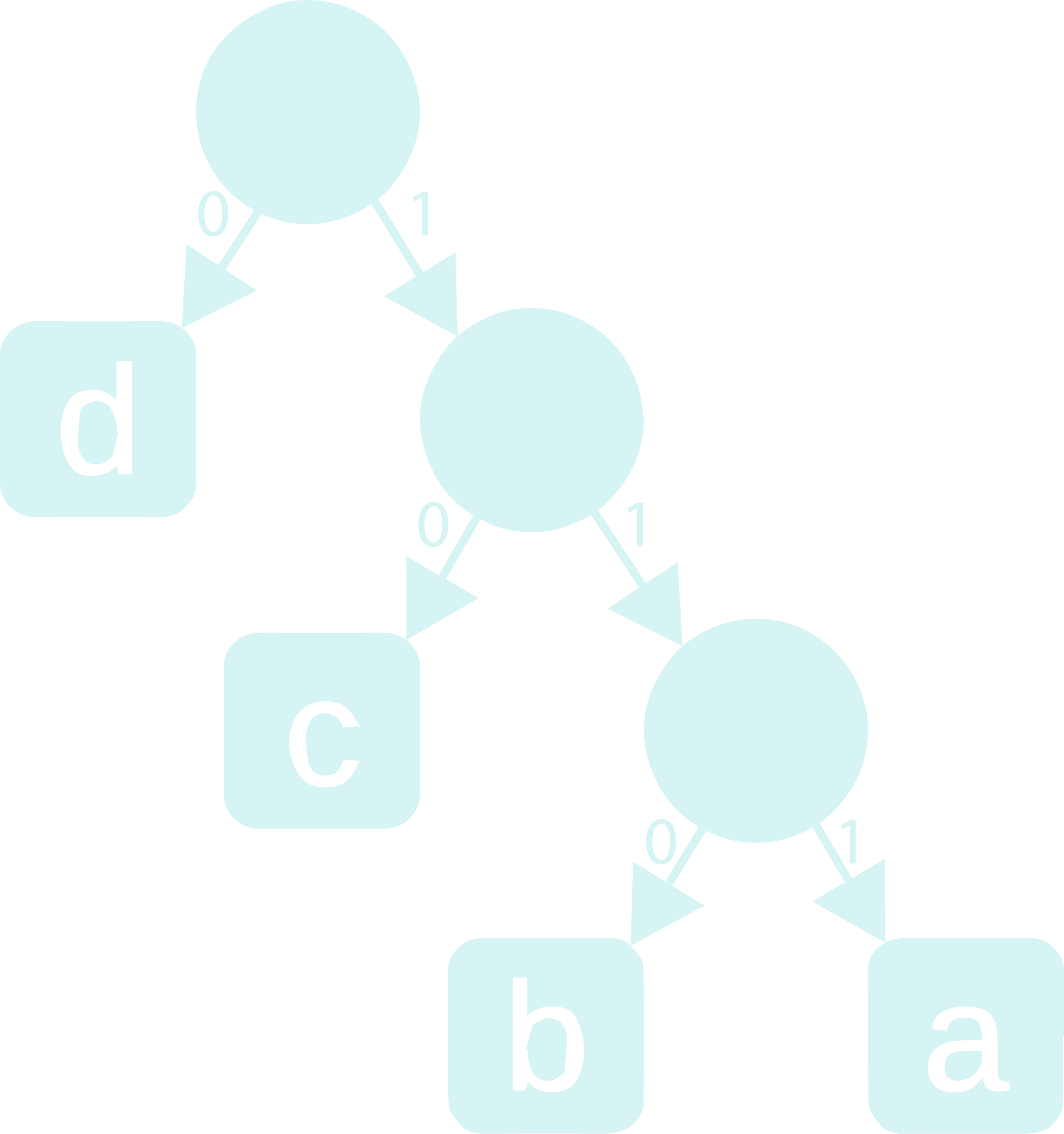
Step - 5: Now that the tree is formed, label all the edges that connect a node and it’s left child as 0 and those that connect a node and it’s right child as 1.
C++ Code
treeNode*formCharacterTree(treeNode*root, vector<char> characters)
{
if(characters.size() == 1)
root->right = characters[0];
else
{
root->left = characters[0];
characters.erase(characters.begin());
root->right = formCharacterTree(root->right, characters);
}
return root;
}
Finding the code for a character from the tree#
From here, it should be easy to see what the codes might be:
To find the code of a character, start from the root and follow the edges to go to that character. Note down the labels of the edges you touch as you go, in order of their appearance. When you finally reach the character, the string formed by the ordered 0s and 1s, is the code for the character.
Pseudo-Code
- Start from
root. Code is nowNULL. - Check if left child is the character. If yes, append
0to your code and stop. Else, append1to your code and go to right child. - Treat your present node as the $root$ and do previous step till you reach the character.
C++ Code
string findCode(treeNode *root, char x)
{
treeNode *temp = root;
string code;
while(temp->right!=NULL)
{
if(temp->left == x)
{
code.append("0");
break;
}
else
{
code.append("1");
temp = temp->right;
}
}
return code;
}
Going by this logic, the codes for the characters which we have will be:
| Character | Code | Code Length |
|---|---|---|
| d | 0 | 1 |
| c | 10 | 2 |
| b | 110 | 3 |
| a | 111 | 3 |
The length of the string will be (1*4) + (2*3) + (3*2) + (3*1) = 19, is lesser than 20, which was the length of the encoded string if we used fixed length encoding.
But, does this method always work? Does this method of creating the tree and finding the codes always give us codes in such a way that the length of the encoded string will always be minimum? Let us see another example.
Algorithm Rekt#
Let us take a set of characters (again 4 distinct ones) and their frequencies as follows:
| Character | Frequency |
|---|---|
| p | 5 |
| q | 5 |
| r | 5 |
| s | 5 |
A case where all characters appear with equal frequency.
Now, if we use the algorithm we just discussed, we will get:
| Character | Code | Code Length |
|---|---|---|
| p | 0 | 1 |
| q | 10 | 2 |
| r | 110 | 3 |
| s | 111 | 3 |
Now, length of the encoding is (1*5) + (2*5) + (3*5) + (3*5) = 45. Is that the minimum we can get? NO. Consider the fixed length encoding of the characters. We have 4 characters and so will need at least 2 digits in the binary number used to represent a character:
According to fixed length encoding we will get:
| Character | Code | Code Length |
|---|---|---|
| p | 00 | 2 |
| q | 01 | 2 |
| r | 10 | 2 |
| s | 11 | 2 |
Here, total length of encoding is (2*5) + (2*5) + (2*5) + (2*5) = 40. So, by fixed length encoding, which is much much simpler than the algorithm we discussed above, we get a slightly lesser string length (40 vs 45).
Is there an algorithm that will work at all times, no matter what, and will always give the characters a code such that the total length of the encoded string will be as minimum as possible?
This was the problem that David A. Huffman set out to solve, while he was a Sc.D. student at MIT.
The Huffman Way#
The algorithm goes like this:
Step - 1: Create a leaf node (a node with both children as NULL) for every unique character present in the string to be encoded. The nodes have to contain the 2 things in it - the character itself and it’s frequency.
Step - 2: Push each leaf node into a priority queue, in which highest priority is given to the character with the least frequency of appearance.

Step - 3: After pushing all leaf nodes, repeat the following steps (4 - 6) till there is only 1 node in the priority queue.
Step - 4: Pop out the 2 topmost nodes of the priority queue (i.e., the ones with the least frequent characters).

Step - 5: Create a new node with these 2 as it’s children. The left child of this newly created node is the node that was just popped out and appears with the lesser frequency. The right child is the other node that was just popped out.
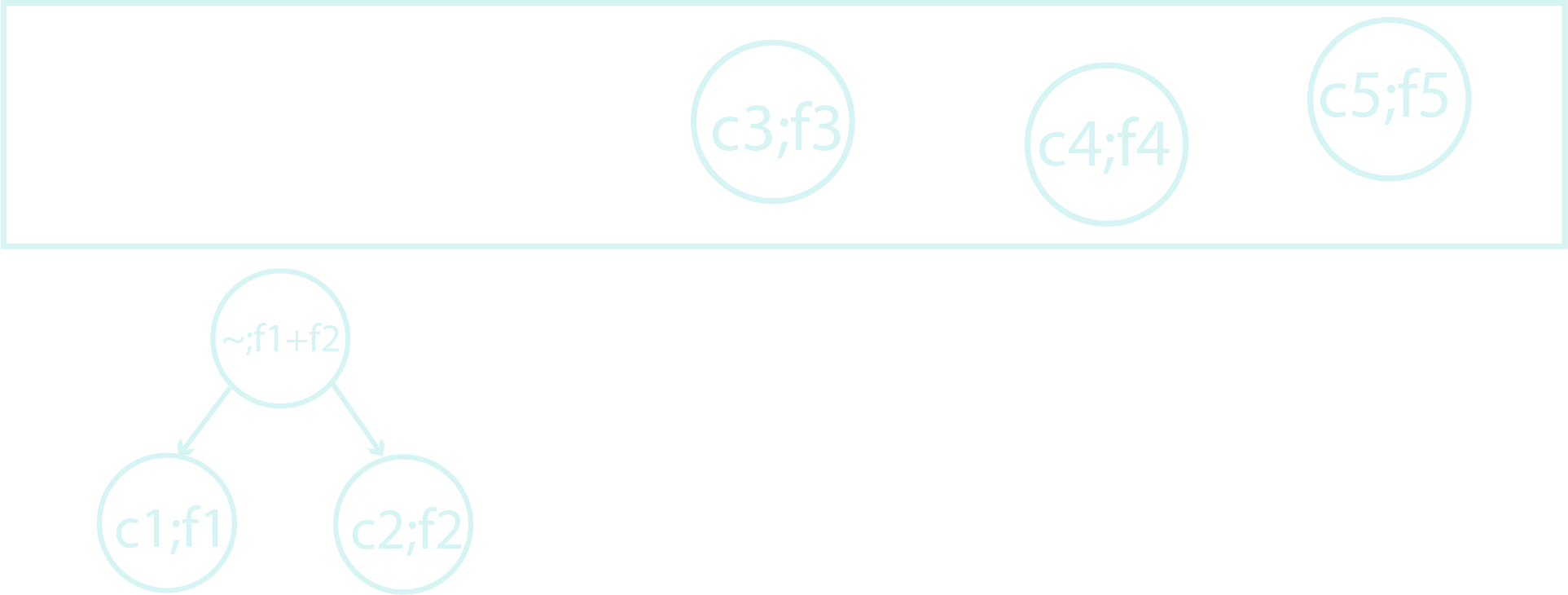
Step - 6: Update the newly created node with frequency as the sum of frequency of it’s children. Assign it with a character that doesn’t occur in the string at all (usually, updated with a rarely appearing character like $~$), or if the programming language supports it, the character can be the combination of the characters of it children.

Step - 7: Now, the character tree is complete. Label all left-edges as $0$ and right-edges as $1$.
To get the code of any character, follow the steps which we had previously discussed to find the code for a character in a labelled tree.
C++ Code#
//data type to store character and it's frequency
typedef struct charWithFreq
{
char ch;
int freq;
} charWithFreq;
//a typical node in the huffman tree
struct huffmanTreeNode
{
charWithFreq data;
struct huffmanTreeNode *left,*right;
huffmanTreeNode(charWithFreq temp)
{
left = right = NULL;
this->data.ch = temp.ch;
this->data.freq = temp.freq;
}
} huffmanTreeNode;
//this is for giving priority to elements in the priority queue
struct heapCompare
{
bool operator()(huffmanTreeNode*l, huffmanTreeNode* r);
{
return (l->data.freq > r->data.freq);
}
} heapCompare;
//function to form the huffman tree, given all characters and their frequencies
void formHuffmanTree(vector<charWithFreq> content)
{
huffmanTreeNode *left,*right, *temp;
priority_queue <huffmanTreeNode*, vector<huffmanTreeNode*>, heapCompare> huffmanTree;
for(int i = 0;i < content.size();++i)
huffmanTree.push(new huffmanTreeNode(content[i]));
while(huffmanTree.size() != 1)
{
left = huffmanTree.top();
huffmanTree.pop();
right = huffmanTree.top();
huffmanTree.pop();
charWithFreq idk;
idk.freq = left->data.freq + right->data.freq;
idk.ch = '~';
temp = new huffmanTreeNode(idk);
temp->left = left;
temp->right = right;
huffmanTree.push(temp);
}
}
If we form the Huffman tree for the characters with frequencies as in Table - 1 , we get:
| Character | Code | Code Length |
|---|---|---|
| a | 111 | 3 |
| b | 110 | 3 |
| c | 10 | 2 |
| d | 0 | 3 |
And length of encoding will be: (1*4) + (2*3) + (3*2) + (3*1) = 19.
Analysis of the Huffman Encoding Algorithm#
What’s the greedy part in this algorithm?#
Well, at each stage we pop out the elements with the least frequencies. Thus, we are being greedy on the frequency of character.
Time Complexity#
We do two processes in the huffman encoding algorithm:
Process 1: We have to first push all characters into the priority queue. This is $\mathcal{O}(n)$.
Process 2: In the while loop, which runs for n times, we have to retrieve and pop the first 2 elements from the priority queue. Getting the first element and popping the first element of a priority queue are $\mathcal{O}(1)$ operations. We then have to create a new node with these as it’s children. Again an $\mathcal{O}(1)$ operation. Then, we have to push it back in the priority queue. Inserting a node in a priority queue is an $\mathcal{O}(log(n))$ operation.
Since we do the insertion n times (in the while loop), the time complexity of this process will be $\mathcal{O}(n \cdot log(n))$.
The overall time complexity of the Huffman Encoding algorithm will thus be $$\text{max} [ \mathcal{O}(n), \mathcal{O}(n \cdot log(n)) ] \ =\ \mathcal{O}(n \cdot log(n))$$
Space Complexity#
Since the algorithm creates a tree with all the distinct characters and their frequencies (more precisely, priority queue), the space complexity is $\mathcal{O}(n)$.
Here is the link to my GitHub repository for this blog post .
References: